
Directive Pipeline
Directives จะถูกวางในไปป์ไลน์และดำเนินการตามลำดับ การออกแบบเริ่มต้นนั้นเรียบง่าย ดังนี้:

ในสถาปัตยกรรมนี้:
- อินพุตของไปป์ไลน์คือค่าของฟิลด์ที่จัดหาโดย field resolver
- แต่ละ directive จะดำเนินการตรรกะและส่งผลลัพธ์ไปยัง directive ถัดไปในไปป์ไลน์
- เอาต์พุตของไปป์ไลน์จะเป็นค่าฟิลด์ที่แก้ไขแล้ว หลังจากผ่านการประมวลผลโดย directive ทั้งหมด
อย่างไรก็ตาม สถาปัตยกรรมนี้ยังไม่ได้ใช้ประโยชน์จาก GraphQL ได้อย่างเต็มที่ ด้านล่างนี้คือคำอธิบายของทุกขั้นตอนจาก directive pipeline จริง จนถึงการออกแบบจริงที่นำมาใช้ใน Gato GraphQL
Directives ในฐานะส่วนประกอบของการแก้ไข queries
ในตอนแรก เราอาจพิจารณาให้ GraphQL server แก้ไขฟิลด์ผ่านกลไกบางอย่าง แล้วส่งค่านี้เป็นอินพุตไปยัง directive pipeline
อย่างไรก็ตาม มันง่ายกว่ามากที่จะมีกลไกเดียวในการจัดการทุกอย่าง: การเรียก field resolvers (ทั้งสำหรับการตรวจสอบฟิลด์และการแก้ไขฟิลด์) สามารถดำเนินการผ่าน directive pipeline ได้แล้ว ในกรณีนี้ directive pipeline จะเป็นกลไกเดียวที่ใช้แก้ไข query
ด้วยเหตุนี้ Gato GraphQL server จึงมี directives พิเศษสองตัว:
@validateเรียก field resolver เพื่อตรวจสอบว่าฟิลด์สามารถแก้ไขได้หรือไม่ (เช่น: ไวยากรณ์ถูกต้อง ฟิลด์มีอยู่ เป็นต้น)- หากสำเร็จ
@resolveValueAndMergeจะเรียก field resolver เพื่อแก้ไขฟิลด์และรวมค่าเข้าไปในออบเจกต์ response
สองตัวนี้เป็น directives ประเภทพิเศษ "system": สงวนไว้สำหรับ GraphQL engine เท่านั้น และใช้งานโดยปริยายในทุกฟิลด์ (ในทางตรงกันข้าม directives มาตรฐานจะเป็นแบบชัดเจน: เพิ่มโดยผู้ใช้ใน query)
โดยใช้ directives สองตัวนี้ query นี้:
query {
field1
field2 @directiveA
}...จะถูกแก้ไขเป็น:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge @directiveA
}ตอนนี้ไปป์ไลน์มีลักษณะดังนี้ (โปรดสังเกตว่าไปป์ไลน์รับฟิลด์เป็นอินพุต ไม่ใช่ค่าที่แก้ไขเริ่มต้น):

Pipeline Slots
Directives มักจะถูกดำเนินการหลังจาก @resolveValueAndMerge เนื่องจากส่วนใหญ่เกี่ยวข้องกับการอัปเดตค่าของฟิลด์ที่แก้ไขแล้ว อย่างไรก็ตาม มี directives อื่นๆ ที่ต้องดำเนินการก่อน @validate หรือระหว่าง @validate กับ @resolveValueAndMerge
ตัวอย่างเช่น:
- เพื่อวัดเวลาที่ใช้ในการแก้ไขฟิลด์ directive
@traceExecutionTimeสามารถรับเวลาปัจจุบันก่อนและหลังการแก้ไขฟิลด์ได้ โดยวาง subdirectives@startTracingExecutionTimeไว้ที่จุดเริ่มต้นและ@endTracingExecutionTimeไว้ที่จุดสิ้นสุดของไปป์ไลน์ - Directive
@cacheต้องตรวจสอบว่าฟิลด์ที่ร้องขอถูก cache ไว้หรือไม่และส่งคืน response นั้นก่อนดำเนินการ@resolveValueAndMerge
จากนั้นไปป์ไลน์จะมี slot ที่แตกต่างกันห้า slot ผ่านคลาส PipelinePositions และ directive จะระบุว่าต้องดำเนินการใน slot ใด:
- Slot
"beginning": ที่จุดเริ่มต้น - Slot
"before-validate": ก่อนการตรวจสอบ - Slot
"middle": หลังการตรวจสอบและก่อนการแก้ไขฟิลด์ - Slot
"after-resolve": หลังการแก้ไขฟิลด์ - Slot
"end": ที่จุดสิ้นสุด
ตอนนี้ directive pipeline มีลักษณะดังนี้ (พิจารณาเพียง 3 ขั้นตอนเพื่อความเรียบง่าย):

โปรดสังเกตว่า directives @skip และ @include สามารถทำได้ง่ายมากด้วยสถาปัตยกรรมนี้: เมื่อวางอยู่ใน slot "middle" สามารถแจ้ง directive @resolveValueAndMerge (พร้อมกับ directives ทั้งหมดในขั้นตอนถัดไปของไปป์ไลน์) ให้ไม่ดำเนินการโดยตั้งค่า flag skipExecution เป็น true
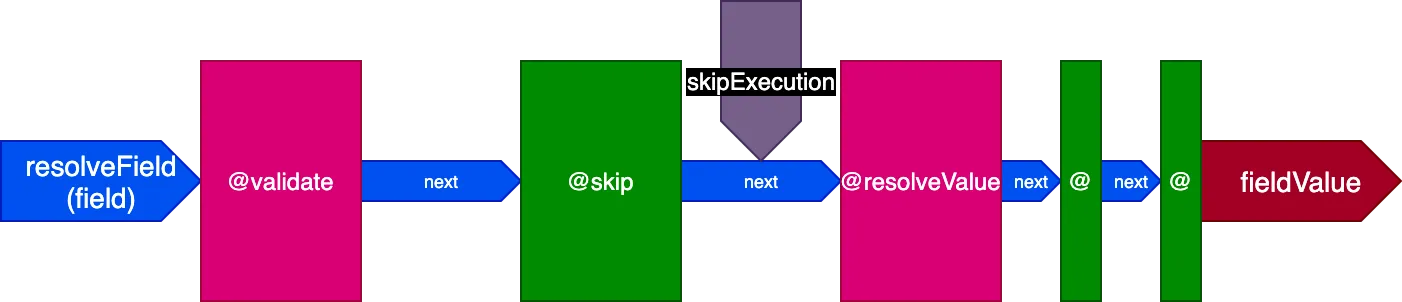
การดำเนินการ Directive บนหลายฟิลด์ในการเรียกครั้งเดียว
จนถึงตอนนี้ เราพิจารณาฟิลด์เดียวที่เป็นอินพุตของ directive pipeline อย่างไรก็ตาม ใน GraphQL query ทั่วไป เราจะได้รับหลายฟิลด์ที่ต้องดำเนินการ directives
ตัวอย่างเช่น ใน query ด้านล่าง directive @upperCase จะถูกดำเนินการบนฟิลด์ "field1" และ "field2":
query {
field1 @upperCase
field2 @upperCase
field3
}ยิ่งไปกว่านั้น เนื่องจาก GraphQL engine เพิ่ม system directives @validate และ @resolveValueAndMerge ไปยังทุกฟิลด์ใน query ดังนั้น query นี้:
query {
field1
field2
field3
}...จะถูกแก้ไขเป็น query นี้:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}ดังนั้น system directives จะรับทุกฟิลด์เป็นอินพุตเสมอ
เป็นผลให้ directive pipeline ถูกออกแบบให้รับหลายฟิลด์เป็นอินพุต ไม่ใช่แค่ครั้งละหนึ่งฟิลด์:

สถาปัตยกรรมนี้มีประสิทธิภาพมากกว่า เพราะการดำเนินการ directive เพียงครั้งเดียวสำหรับทุกฟิลด์นั้นเร็วกว่าการดำเนินการครั้งละหนึ่งฟิลด์ และจะให้ผลลัพธ์เดียวกัน
ตัวอย่างเช่น เมื่อตรวจสอบว่าผู้ใช้เข้าสู่ระบบหรือไม่เพื่อให้สิทธิ์เข้าถึง schema การดำเนินการสามารถทำได้เพียงครั้งเดียว การรันโค้ดต่อไปนี้:
if (isUserLoggedIn()) {
resolveFields([$field1, $field2, $field3]);
}มีประสิทธิภาพมากกว่าการรันโค้ดนี้:
if (isUserLoggedIn()) {
resolveField($field1);
}
if (isUserLoggedIn()) {
resolveField($field2);
}
if (isUserLoggedIn()) {
resolveField($field3);
}สิ่งนี้อาจไม่ใช่เรื่องใหญ่เมื่อเรียกฟังก์ชันท้องถิ่นอย่าง isUserLoggedIn อย่างไรก็ตาม มันสามารถสร้างความแตกต่างได้มากเมื่อโต้ตอบกับบริการภายนอก เช่น เมื่อแก้ไข REST endpoints ผ่าน GraphQL ในกรณีเหล่านี้ การดำเนินการฟังก์ชันครั้งเดียวแทนที่จะหลายครั้งอาจสร้างความแตกต่างระหว่างความสามารถในการให้บริการฟังก์ชันบางอย่างหรือไม่
ลองดูตัวอย่าง เมื่อโต้ตอบกับ Google Translate ผ่าน directive @translate GraphQL API ต้องสร้างการเชื่อมต่อผ่านเครือข่าย ดังนั้นการดำเนินการโค้ดนี้จะเร็วที่สุดเท่าที่จะเป็นไปได้:
googleTranslateFields([$field1, $field2, $field3]);ในทางตรงกันข้าม การดำเนินการฟังก์ชันแยกกันหลายครั้งจะสร้าง latency ที่สูงขึ้นซึ่งส่งผลให้เวลาตอบสนองสูงขึ้น ลดประสิทธิภาพของ API นี้อาจไม่ใช่ความแตกต่างที่ใหญ่สำหรับการแปล 3 สตริง (ที่ฟิลด์คือสตริงที่จะแปล) แต่สำหรับ 100 สตริงขึ้นไปจะส่งผลแน่นอน:
googleTranslateField($field1);
googleTranslateField($field2);
googleTranslateField($field3);นอกจากนี้ การดำเนินการฟังก์ชันครั้งเดียวพร้อมอินพุตทั้งหมดอาจให้ผลลัพธ์ที่ดีกว่าการดำเนินการฟังก์ชันบนแต่ละฟิลด์แยกกัน โดยใช้ Google Translate เป็นตัวอย่างอีกครั้ง การแปลจะแม่นยำยิ่งขึ้นเมื่อเรายิ่งให้ข้อมูลแก่บริการมากขึ้น
ตัวอย่างเช่น เมื่อดำเนินการโค้ดด้านล่าง:
googleTranslate("fork");
googleTranslate("road");
googleTranslate("sign");สำหรับการดำเนินการแยกครั้งแรก Google ไม่รู้บริบทของ "fork" ดังนั้นอาจตอบกลับด้วย fork ในฐานะอุปกรณ์กิน การแยกแยกของถนน หรือความหมายอื่น อย่างไรก็ตาม หากเราดำเนินการแทนว่า:
googleTranslate(["fork", "road", "sign"]);จากข้อมูลที่กว้างขึ้นนี้ Google สามารถอนุมานได้ว่า "fork" หมายถึงการแยกแยะของถนน และส่งคืนการแปลที่แม่นยำ
ด้วยเหตุผลเหล่านี้ directives ในไปป์ไลน์จึงรับฟิลด์อินพุตทั้งหมดพร้อมกัน และแต่ละ directive สามารถตัดสินใจวิธีที่ดีที่สุดในการรันตรรกะบนอินพุตเหล่านี้ (การดำเนินการครั้งเดียวต่ออินพุต การดำเนินการครั้งเดียวที่ครอบคลุมอินพุตทั้งหมด หรืออะไรก็ตามระหว่างนั้น)
ตอนนี้ไปป์ไลน์มีลักษณะดังนี้:
การดำเนินการ Directive Pipeline เดียวสำหรับ Query ทั้งหมด
เราเพิ่งเรียนรู้ว่ามันสมเหตุสมผลที่จะดำเนินการหลายฟิลด์ต่อ directive อย่างไรก็ตาม สิ่งนี้ทำงานได้ดีตราบเท่าที่ทุกฟิลด์มี directives เดียวกันถูกใช้งาน เมื่อ directives แตกต่างกัน อาจนำไปสู่ความซับซ้อนที่มากขึ้นซึ่งทำให้การนำไปใช้งานยากขึ้น และลดประโยชน์บางส่วนที่ได้รับ
ลองดูว่าสิ่งนี้เกิดขึ้นได้อย่างไร พิจารณา query ต่อไปนี้:
query {
field1 @directiveA
field2
field3
}Directive นี้เทียบเท่ากับ:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}ในสถานการณ์นี้ ฟิลด์ field2 และ field3 มีชุด directives เดียวกัน และ field1 มีชุดที่แตกต่างกัน ดังนั้นเราจำเป็นต้องสร้างไปป์ไลน์ที่แตกต่างกัน 2 อันเพื่อแก้ไข query:
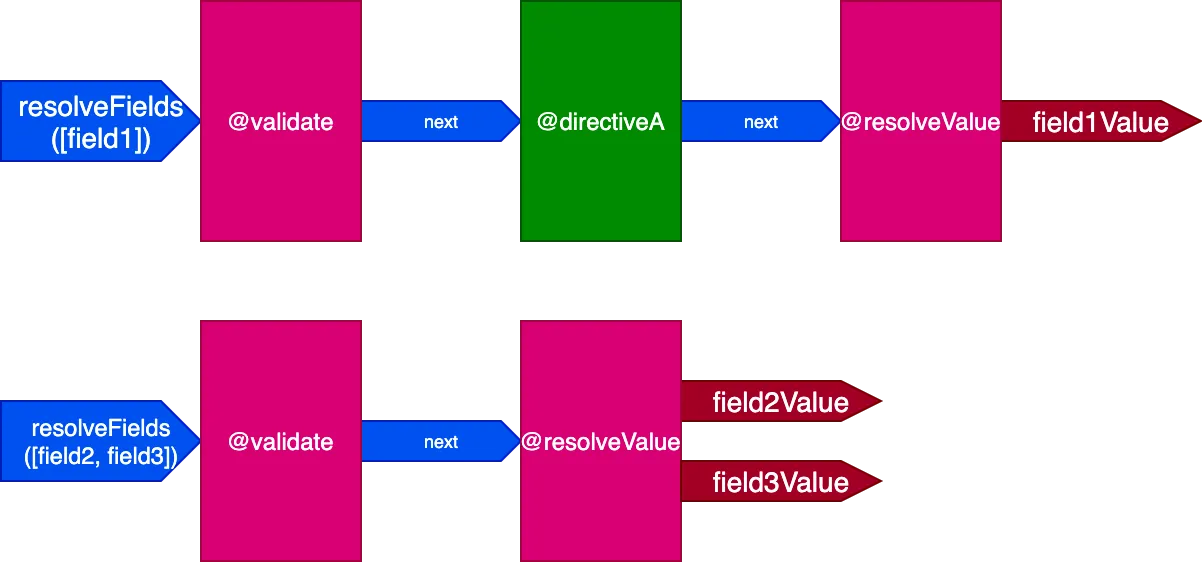
และเมื่อทุกฟิลด์มีชุด directives ที่ไม่ซ้ำกัน ผลกระทบจะชัดเจนมากขึ้น พิจารณา query นี้:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}ซึ่งเทียบเท่ากับ:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge @directiveB @directiveC
field3 @validate @resolveValueAndMerge @directiveC
}ในสถานการณ์นี้ เราจะมี 3 ไปป์ไลน์เพื่อจัดการ 3 ฟิลด์ ดังนี้:
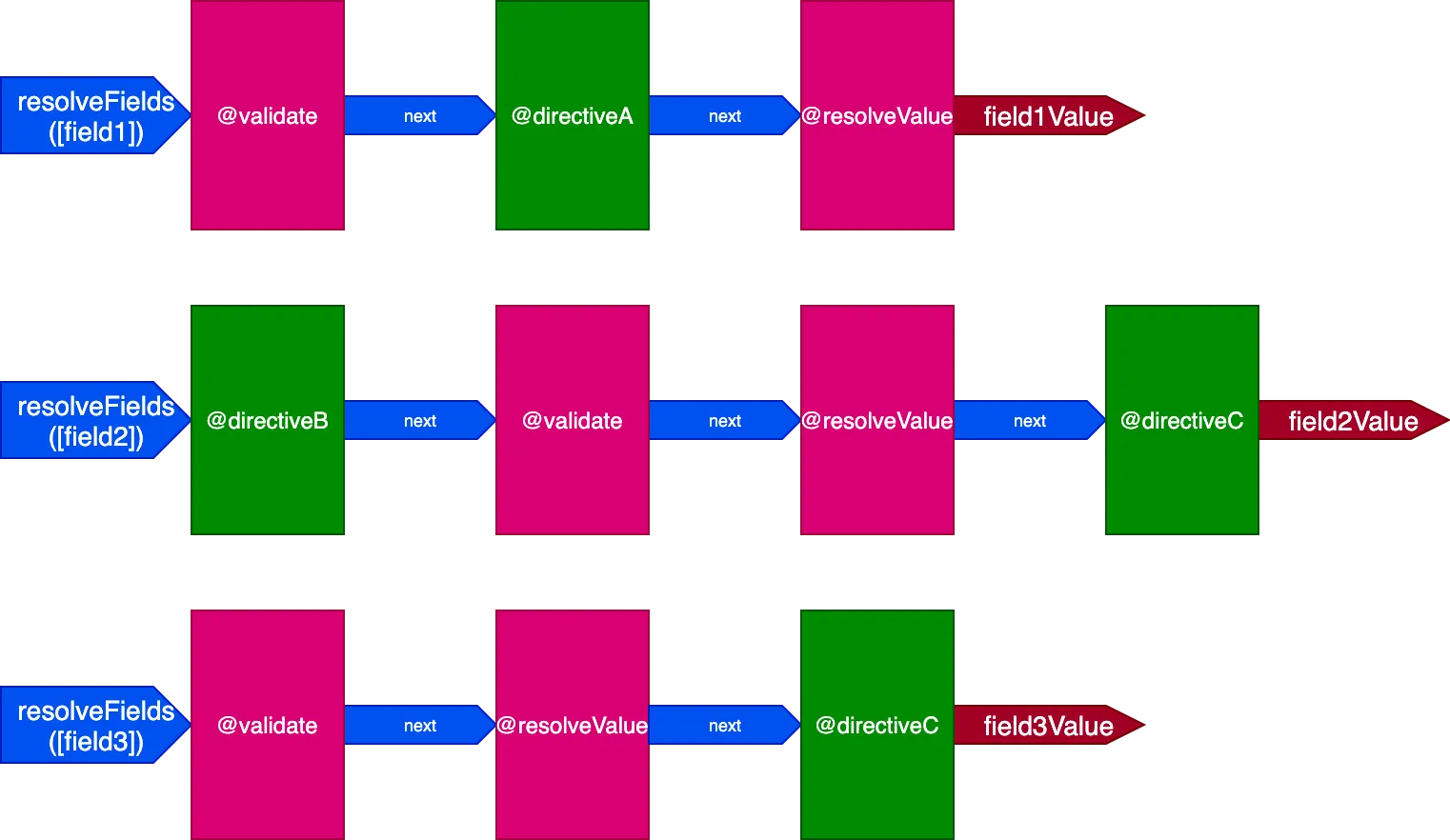
ในกรณีนี้ แม้ว่า directives @validate และ @resolveValueAndMerge จะถูกใช้งานบนทั้ง 3 ฟิลด์ เนื่องจากดำเนินการผ่าน directive pipelines ที่แตกต่างกัน 3 อัน พวกมันจะถูกดำเนินการอย่างอิสระต่อกัน ซึ่งนำเรากลับสู่การมี directive ที่ดำเนินการบนรายการเดียวในแต่ละครั้ง
วิธีแก้ปัญหานี้คือหลีกเลี่ยงการสร้างไปป์ไลน์หลายอัน แต่จัดการด้วยไปป์ไลน์เดียวสำหรับทุกฟิลด์ เป็นผลให้ engine ไม่ส่งฟิลด์เป็นอินพุตไปยังไปป์ไลน์อีกต่อไป เนื่องจากไม่ใช่ directives ทั้งหมดจากไปป์ไลน์เดียวจะโต้ตอบกับชุดฟิลด์เดียวกัน แต่แต่ละ directive ต้องรับรายการฟิลด์ของตัวเองเป็นอินพุตของตัวเอง
จากนั้น สำหรับ query นี้:
query {
field1 @directiveA
field2
field3
}...directives @validate และ @resolveValueAndMerge จะรับทั้ง 3 ฟิลด์เป็นอินพุต และ directiveA จะรับเพียง "field1":
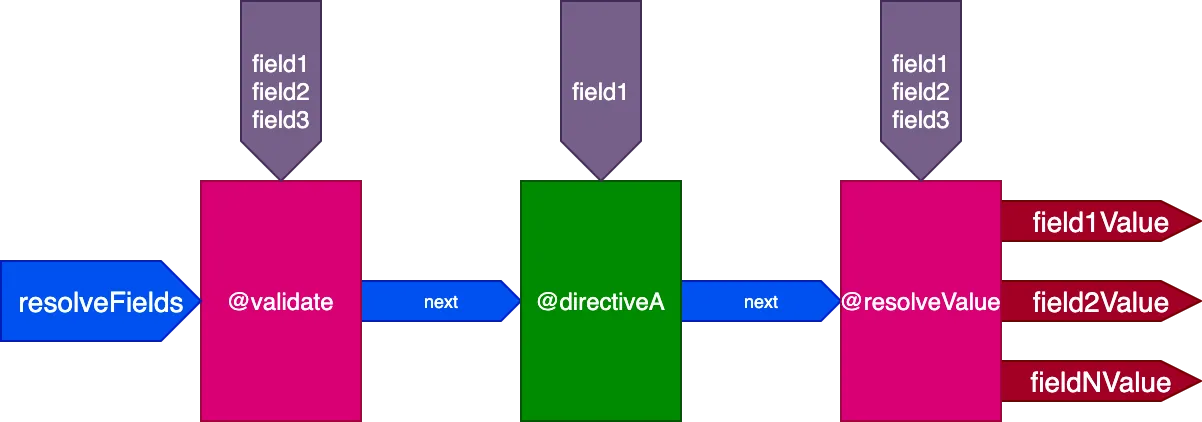
และสำหรับ query นี้:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}...directives @validate และ @resolveValueAndMerge จะรับทั้ง 3 ฟิลด์เป็นอินพุต directiveA จะรับเพียง "field1" directiveB จะรับเพียง "field2" และ directiveC จะรับ "field2" และ "field3":
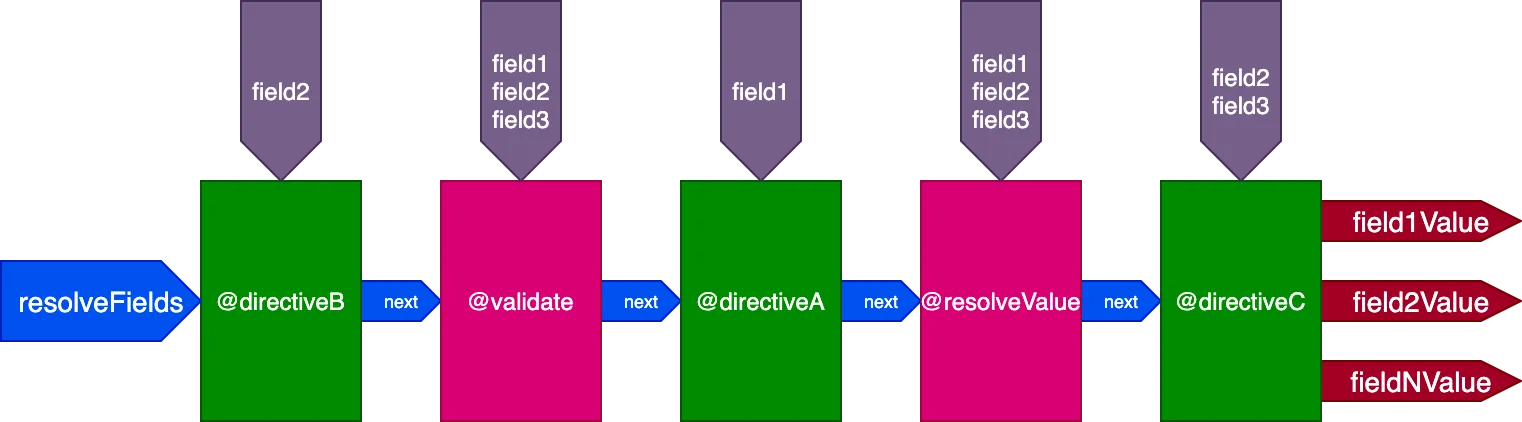
การควบคุมการดำเนินการ Directive ทีละ ID
จนถึงตอนนี้ directive ในขั้นตอนหนึ่งสามารถมีอิทธิพลต่อการดำเนินการของ directives ในขั้นตอนถัดไปผ่าน flag skipExecution อย่างไรก็ตาม flag นี้ไม่ละเอียดเพียงพอสำหรับทุกกรณี
ตัวอย่างเช่น พิจารณา directive @cache ที่วางอยู่ใน slot "end" เพื่อเก็บค่าฟิลด์ เพื่อให้ครั้งถัดไปที่ฟิลด์ถูก query ค่าของมันสามารถดึงมาจาก cache ผ่าน directive @getCache ที่วางอยู่ใน slot "middle":
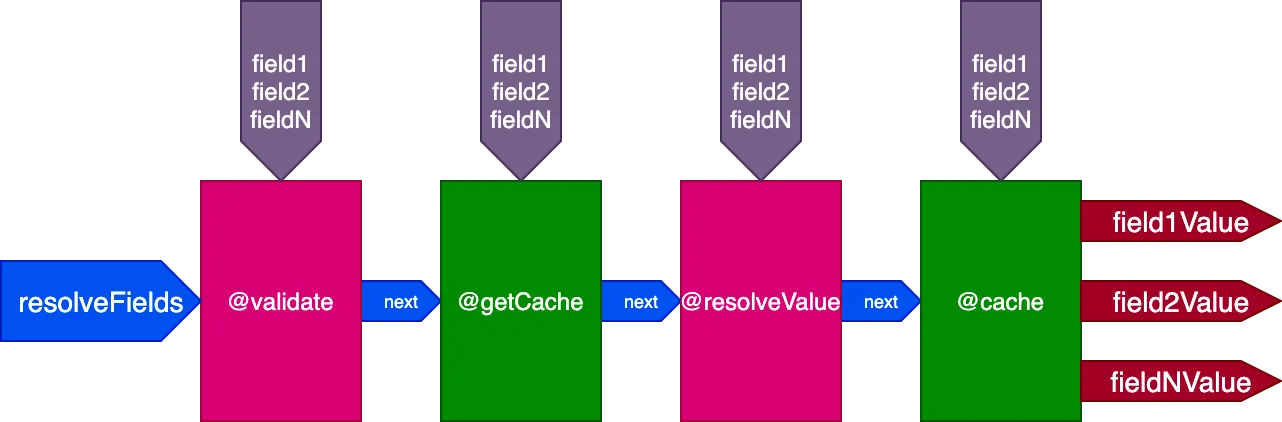
เมื่อดำเนินการ query นี้:
{
posts(pagination: { limit: 2 }) {
title @translate @cache
}
}Server จะดึงและ cache 2 records จากนั้นเราดำเนินการ query เดียวกันแต่ใช้กับ 4 records:
{
posts(pagination: { limit: 4 }) {
title @translate @cache
}
}เมื่อดำเนินการ query ที่ 2 นี้ 2 records จาก query ที่ 1 ถูก cache ไว้แล้ว แต่อีก 2 records ยังไม่ได้ cache อย่างไรก็ตาม เราจำเป็นต้องมี 4 records ทั้งหมดที่ถูก cache ไว้แล้วเพื่อใช้ flag skipExecution มันจะดีกว่าถ้าเราสามารถดึง 2 records แรกจาก cache และแก้ไขเพียง 2 records อื่นๆ เท่านั้น
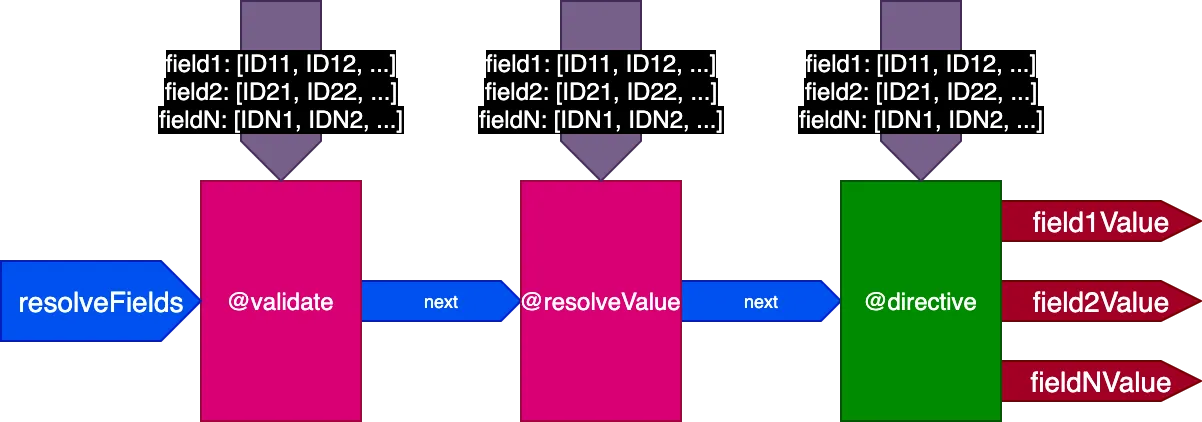
ดังนั้นเราอัปเดตการออกแบบของไปป์ไลน์อีกครั้ง เราเลิกใช้ flag skipExecution และแทนที่จะส่งรายการ object IDs ต่อฟิลด์ที่ directive ต้องถูกใช้งานไปยังแต่ละ directive ผ่านออบเจกต์อินพุต fieldIDs:
{
field1: [ID11, ID12, ...],
field2: [ID21, ID22, ...],
...
fieldN: [IDN1, IDN2, ...],
}ตัวแปร fieldIDs มีเอกลักษณ์สำหรับแต่ละ directive และทุก directive สามารถแก้ไข instance ของ fieldIDs สำหรับ directives ทั้งหมดในขั้นตอนถัดไปได้ จากนั้น skipExecution สามารถทำได้อย่างละเอียดทีละ ID โดยเพียงแค่ลบ ID ออกจาก fieldIDs สำหรับ directives ที่กำลังจะมาในสแต็ก
ตอนนี้ไปป์ไลน์มีลักษณะดังนี้:
เมื่อใช้กับตัวอย่างก่อนหน้า เมื่อดำเนินการ query แรกที่แปล 2 records ไปป์ไลน์จะมีลักษณะดังนี้:
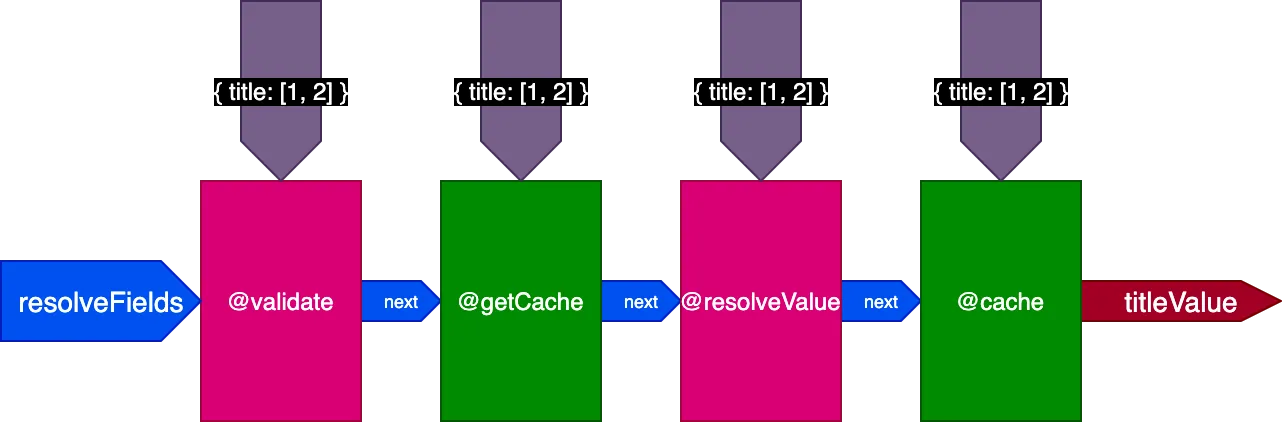
เมื่อดำเนินการ query ที่สองที่แปล 4 records directive @getCache จะรับ IDs ของทั้ง 4 records แต่ทั้ง @resolveValueAndMerge และ @cache จะรับเพียง IDs ของ 2 records สุดท้ายเท่านั้น (ที่ยังไม่ได้ cache):
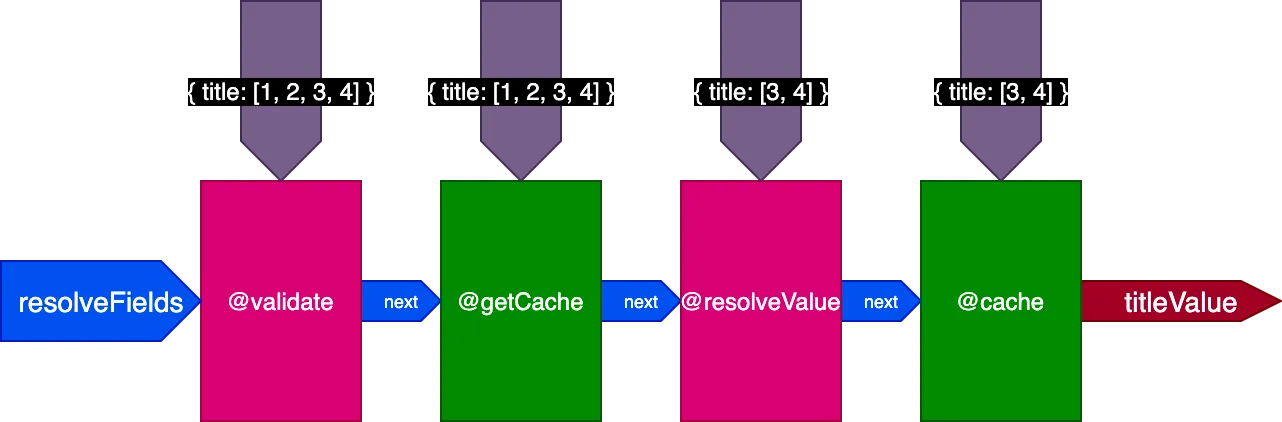
การรวมทุกอย่างเข้าด้วยกัน
นี่คือการออกแบบขั้นสุดท้ายของ directive pipeline:
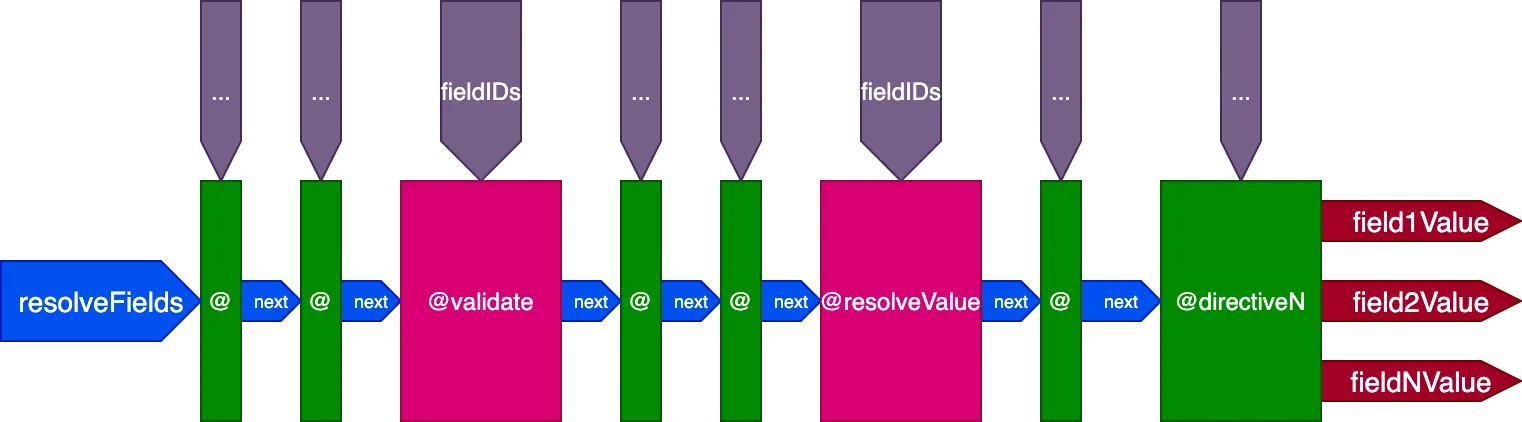
สรุปแล้ว คุณลักษณะของมันมีดังนี้:
- Field resolvers ถูกเรียกจากภายใน directive pipeline ผ่าน directives
@validateและ@resolveValueAndMerge - Directives สามารถวางในหนึ่งใน 5 slots ได้แก่:
"beginning","before-validate","middle","after-validate"และ"end" - Directives แก้ไขหลายฟิลด์ในการเรียกครั้งเดียว
- ไปป์ไลน์เดียวประกอบด้วย directives ทั้งหมดที่เกี่ยวข้องใน query
- แต่ละ directive รับชุด IDs ของตัวเองเพื่อแก้ไขต่อฟิลด์ผ่านตัวแปร
fieldIDs - Directives สามารถแก้ไขตัวแปร
fieldIDsสำหรับ directives ทั้งหมดในขั้นตอนถัดไปของไปป์ไลน์