
เอนจิ้นโหลดข้อมูล
Gato GraphQL ใช้คอมโพเนนต์ฝั่งเซิร์ฟเวอร์ เพื่อแสดงโมเดลข้อมูล (ไม่ใช่กราฟหรือต้นไม้) มาดูกันว่ากระบวนการโหลดข้อมูลดำเนินการอย่างไรเพื่อแก้ไข GraphQL query
เพื่อประมวลผลข้อมูล เราต้องแปลงคอมโพเนนต์ให้เป็นประเภท (types) (<FeaturedDirector> => Director, <Film> => Film, <Actor> => Actor) จัดเรียงตามลำดับที่ปรากฏในลำดับชั้นคอมโพเนนต์ (Director, จากนั้น Film, จากนั้น Actor) และจัดการกับมันใน "การวนซ้ำ" (iterations) โดยดึงข้อมูลออบเจกต์สำหรับแต่ละประเภทในการวนซ้ำของตัวเอง ดังนี้:

เอนจิ้นโหลดข้อมูลของเซิร์ฟเวอร์ต้องใช้อัลกอริทึม (เทียม) ต่อไปนี้เพื่อโหลดข้อมูล:
การเตรียมการ:
- เตรียมคิวว่างเพื่อเก็บรายการ ID ของออบเจกต์ที่ต้องดึงจากฐานข้อมูล จัดระเบียบตามประเภท (แต่ละรายการจะเป็น:
[type => list of IDs]) - ดึง ID ของออบเจกต์ผู้กำกับที่โดดเด่น และวางมันในคิวภายใต้ประเภท
Director
วนซ้ำจนกว่าจะไม่มีรายการในคิว:
- ดึงรายการแรกจากคิว: ประเภทและรายการ ID (เช่น:
Directorและ[2]) และลบรายการนี้ออกจากคิว - ใช้ออบเจกต์
TypeDataLoaderของประเภทนั้น ดำเนินการ query เดียวกับฐานข้อมูลเพื่อดึงออบเจกต์ทั้งหมดของประเภทนั้นที่มี ID เหล่านั้น - หากประเภทมีฟิลด์เชิงสัมพันธ์ (เช่น: ประเภท
Directorมีฟิลด์เชิงสัมพันธ์filmsของประเภทFilm) ให้รวบรวม ID ทั้งหมดจากฟิลด์เหล่านี้จากออบเจกต์ทั้งหมดที่ดึงมาในการวนซ้ำปัจจุบัน (เช่น: ID ทั้งหมดในฟิลด์filmsจากออบเจกต์ทั้งหมดของประเภทDirector) และวาง ID เหล่านี้ในคิวภายใต้ประเภทที่สอดคล้องกัน (เช่น: ID[3, 8]ภายใต้ประเภทFilm)
เมื่อสิ้นสุดการวนซ้ำ เราจะโหลดข้อมูลออบเจกต์ทั้งหมดสำหรับทุกประเภท ดังนี้:
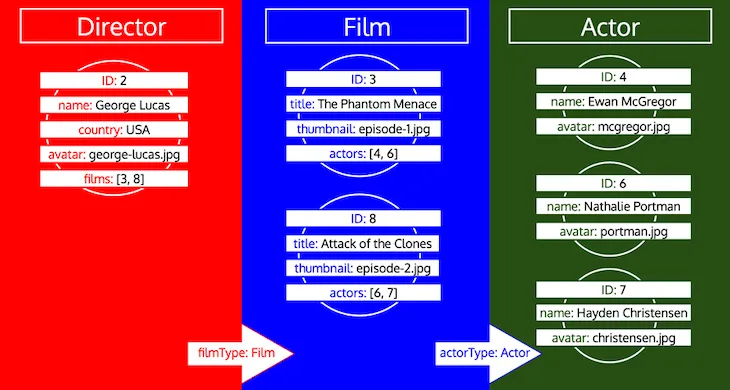
โปรดสังเกตว่า ID ทั้งหมดสำหรับประเภทหนึ่งจะถูกรวบรวมจนกว่าประเภทนั้นจะถูกประมวลผลในคิว ตัวอย่างเช่น หากเราเพิ่มฟิลด์เชิงสัมพันธ์ preferredActors ให้กับประเภท Director ID เหล่านี้จะถูกเพิ่มในคิวภายใต้ประเภท Actor และจะถูกประมวลผลร่วมกับ ID จากฟิลด์ actors ของประเภท Film:
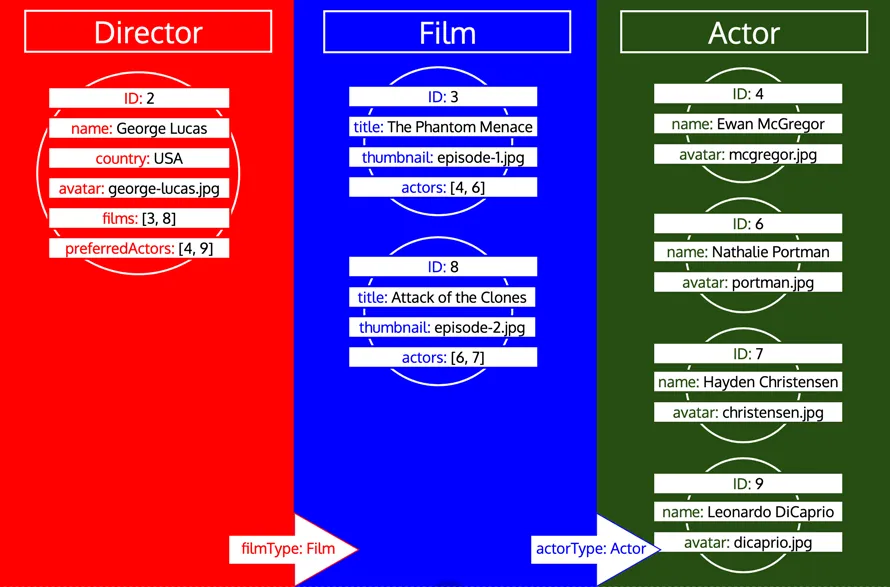
อย่างไรก็ตาม หากประเภทถูกประมวลผลแล้วและจำเป็นต้องโหลดข้อมูลเพิ่มเติมจากประเภทนั้น นั่นคือการวนซ้ำใหม่สำหรับประเภทนั้น ตัวอย่างเช่น การเพิ่มฟิลด์เชิงสัมพันธ์ preferredDirector ให้กับประเภท Author จะทำให้ประเภท Director ถูกเพิ่มในคิวอีกครั้ง:
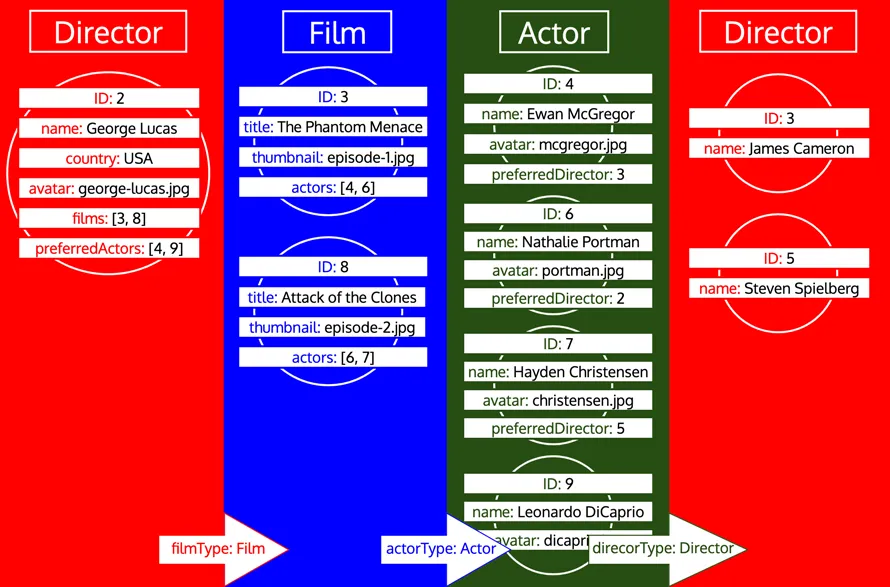
เมื่อดึงข้อมูลออบเจกต์ทั้งหมดแล้ว เราต้องจัดรูปแบบให้เป็นการตอบสนองที่คาดหวัง โดยสะท้อน GraphQL query อย่างไรก็ตาม ดังที่เห็น ข้อมูลไม่มีโครงสร้างต้นไม้ที่จำเป็น แต่ฟิลด์เชิงสัมพันธ์มี ID ไปยังออบเจกต์ที่ซ้อนกัน จำลองวิธีการแสดงข้อมูลในฐานข้อมูลเชิงสัมพันธ์ ดังนั้น เมื่อเปรียบเทียบกัน ข้อมูลที่ดึงมาสำหรับแต่ละประเภทสามารถแสดงเป็นตาราง ดังนี้:
ตารางสำหรับประเภท Director:
| ID | name | country | avatar | films |
|---|---|---|---|---|
| 2 | George Lucas | USA | george-lucas.jpg | [3, 8] |
ตารางสำหรับประเภท Film:
| ID | title | thumbnail | actors |
|---|---|---|---|
| 3 | The Phantom Menace | episode-1.jpg | [4, 6] |
| 8 | Attack of the Clones | episode-2.jpg | [6, 7] |
ตารางสำหรับประเภท Actor:
| ID | name | avatar |
|---|---|---|
| 4 | Ewan McGregor | mcgregor.jpg |
| 6 | Nathalie Portman | portman.jpg |
| 7 | Hayden Christensen | christensen.jpg |
เมื่อจัดระเบียบข้อมูลทั้งหมดเป็นตาราง และรู้ว่าแต่ละประเภทเกี่ยวข้องกันอย่างไร (กล่าวคือ Director อ้างอิง Film ผ่านฟิลด์ films, Film อ้างอิง Actor ผ่านฟิลด์ actors) เซิร์ฟเวอร์ GraphQL สามารถแปลงข้อมูลเป็นรูปแบบต้นไม้ที่คาดหวังได้อย่างง่ายดาย:
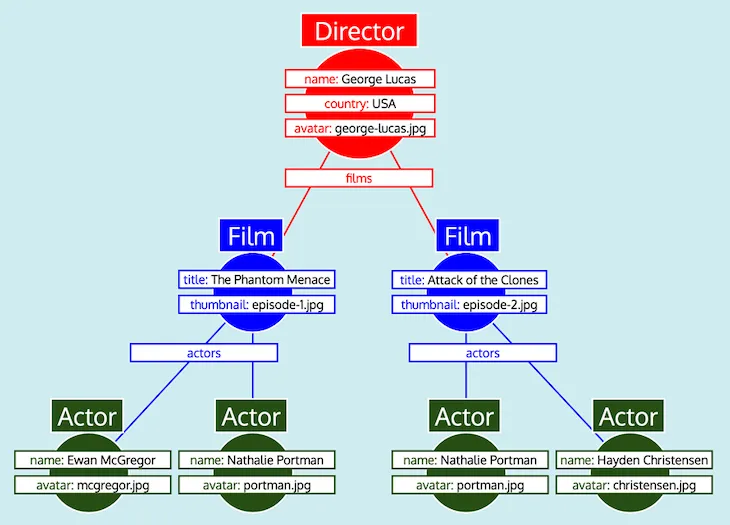
สุดท้าย เซิร์ฟเวอร์ GraphQL จะส่งออกต้นไม้ ซึ่งมีรูปแบบของการตอบสนองที่คาดหวัง:
{
data: {
featuredDirector: {
name: "George Lucas",
country: "USA",
avatar: "george-lucas.jpg",
films: [
{
title: "Star Wars: Episode I",
thumbnail: "episode-1.jpg",
actors: [
{
name: "Ewan McGregor",
avatar: "mcgregor.jpg",
},
{
name: "Natalie Portman",
avatar: "portman.jpg",
}
]
},
{
title: "Star Wars: Episode II",
thumbnail: "episode-2.jpg",
actors: [
{
name: "Natalie Portman",
avatar: "portman.jpg",
},
{
name: "Hayden Christensen",
avatar: "christensen.jpg",
}
]
}
]
}
}
}การวิเคราะห์ความซับซ้อนของเวลาของโซลูชัน
มาวิเคราะห์สัญกรณ์บิ๊กโอ ของอัลกอริทึมโหลดข้อมูลเพื่อทำความเข้าใจว่าจำนวน queries ที่ดำเนินการกับฐานข้อมูลเพิ่มขึ้นอย่างไรเมื่อจำนวนอินพุตเพิ่มขึ้น เพื่อให้แน่ใจว่าโซลูชันนี้มีประสิทธิภาพ
เอนจิ้นโหลดข้อมูลโหลดข้อมูลในการวนซ้ำที่สอดคล้องกับแต่ละประเภท เมื่อเริ่มการวนซ้ำ จะมีรายการ ID ทั้งหมดสำหรับออบเจกต์ทั้งหมดที่ต้องดึงอยู่แล้ว ดังนั้นจึงสามารถดำเนินการ query เดียวเพื่อดึงข้อมูลทั้งหมดสำหรับออบเจกต์ที่สอดคล้องกัน จากนั้นจะเห็นได้ว่าจำนวน queries กับฐานข้อมูลจะเพิ่มขึ้นเชิงเส้นตามจำนวนประเภทที่เกี่ยวข้องใน query กล่าวอีกนัยหนึ่ง ความซับซ้อนของเวลาคือ O(n) โดย n คือจำนวนประเภทใน query (อย่างไรก็ตาม หากประเภทถูกวนซ้ำมากกว่าหนึ่งครั้ง ก็ต้องเพิ่มมากกว่าหนึ่งครั้งใน n)
โซลูชันนี้มีประสิทธิภาพสูงมาก ดีกว่าความซับซ้อนแบบเอกซ์โพเนนเชียลที่คาดหวังจากการจัดการกับกราฟ หรือความซับซ้อนแบบลอการิทึมที่คาดหวังจากการจัดการกับต้นไม้
โค้ด PHP ที่ใช้งาน
กระบวนการโหลดข้อมูลเกิดขึ้นในฟังก์ชัน getComponentData จากคลาส Engine ในแพ็คเกจ Component Model